9 Top Serverless GPU Cloud Platforms in 2025
With demand for Serverless GPU platforms surging, AI engineers can now run on‑demand inference without worrying about infrastructure management. This article compares top providers including RunPod, Modal, Replicate, Novita AI, fal.ai, Baseten, Koyeb, and Zhilingyun, helping you choose the best solution for your 2025 AI compute needs.
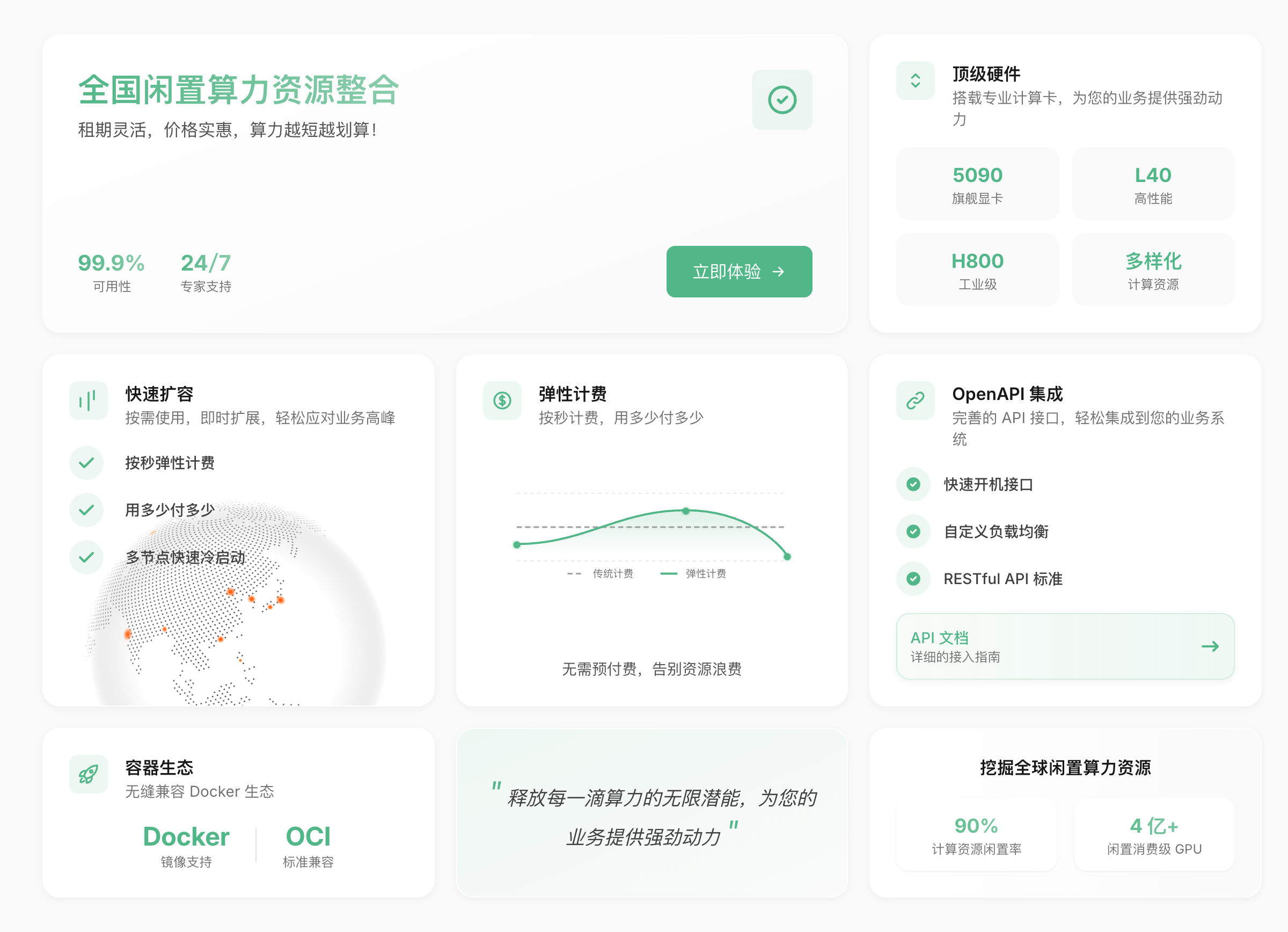
Gongji Compute: Empower AI with idle compute
Portal: https://www.gongjiyun.com?utm_campaign=nexmoe
Gongji Tech is a cloud platform focused on elastic GPU compute services. It integrates global idle compute resources to deliver cost‑effective solutions for AI training, video transcoding, scientific computing, and more. Built by a team with Tsinghua background, it uses dynamic scaling and per‑second billing. Highlights include NVIDIA RTX 4090‑class hardware, flexible pricing, a complete container ecosystem, 99.9% availability, and 24/7 professional support. It has served AI teams at Tsinghua University, Huawei, and other organizations.
- Uses idle resources, dynamic scaling, and per‑second billing, reducing costs by up to 70% vs traditional models
- Supports top hardware such as NVIDIA 5090/L40/H800 for diverse AI workloads
- Offers full OpenAPI + Docker ecosystem integration for easy system integration
RunPod: One‑stop AI training & deployment cloud

Portal: https://www.runpod.io
RunPod is a cloud platform built for AI workloads, offering end‑to‑end training and deployment. It supports global distributed GPU resources, preconfigured environments for PyTorch/TensorFlow, and custom containers. RunPod emphasizes fast deployment and cost efficiency, with server start times in milliseconds and 50+ ready‑to‑use templates. Its Serverless GPU offering provides cold starts under 250ms, ideal for elastic inference. It also provides special credit programs for startups and academia.
- Fast deployment: GPU pods start in seconds, cold starts down to milliseconds
- Rich options: 50+ preconfigured templates, mainstream ML frameworks, custom containers
- Cost‑effective: multiple GPU options starting at $0.16/hr
Modal: One‑line AI deployment in the cloud

Portal: https://modal.com
Modal is a cloud computing platform for AI developers. Deploy Python functions to the cloud with one line of code and get automatic scaling for ML inference, data processing, and more. It uses a Rust‑based container system for sub‑second startup, can scale to hundreds of GPUs in seconds, and offers per‑second billing.
- Zero‑config deployment via Python decorators
- High‑performance compute with H100/A100 and optimized GPU utilization
- Seamless scaling from zero to thousands of containers
Replicate: One‑click AI model runs in the cloud
Portal: https://replicate.com
Replicate is an open‑source AI model hosting platform with easy APIs, letting developers call pre‑trained AI models with a single line. It aggregates thousands of community models across image generation, video processing, and text creation, optimized for production. Replicate uses per‑second billing and handles GPU scheduling and API deployment, lowering the barrier to AI app development.
- Thousands of production‑ready models like Stable Diffusion and Llama
- Fine‑tuning capabilities with your own data
- Usage‑based pricing with automatic scaling
Explore fal.ai: Developer‑first generative AI platform

Portal: https://fal.ai
fal.ai is a developer‑focused generative AI platform designed for high‑performance, low‑latency media generation. It includes the fal Inference Engine™, running diffusion models up to 4× faster. It supports text‑to‑image, image‑to‑video, and more, with rich model libraries (Kling, Pixverse, etc.), flexible pay‑as‑you‑go pricing, and enterprise customization.
- Ultra‑fast inference: up to 400% speed boost for diffusion models
- Diverse model library: Kling, Veo 2 and more, supports LoRA fine‑tuning
- Developer‑friendly: Python/JavaScript/Swift SDKs, private deployments, H100 billed per second
Baseten: Leading platform for AI inference deployment

Portal: https://www.baseten.co
Baseten focuses on AI inference deployment, providing high‑performance runtime, cross‑cloud availability, and a smooth developer workflow. It supports open‑source, custom, and fine‑tuned models for production needs. With an optimized inference stack, cloud‑native infrastructure, and expert engineering support, Baseten helps many well‑known companies ship AI products quickly.
- Dedicated deployment options for high‑load workloads with seamless scaling
- Custom optimizations for generative AI: image generation, transcription, TTS, etc.
- Flexible deployment modes: Baseten cloud, self‑hosted, or on‑demand
Novita.ai: Efficient AI model deployment platform
Portal: https://novita.ai
Novita.ai provides easy APIs to deploy and scale AI apps. It integrates 200+ open models across chat, code, image, and audio, and supports enterprise custom models. With global GPU distribution and on‑demand architecture, it cuts costs by up to 50% while maintaining performance and stability.
- 200+ ready‑to‑use models via API
- Global GPU resources with A100/RTX4090 options
- On‑demand billing saving up to 50%
Koyeb: Global high‑performance Serverless platform
Portal: https://www.koyeb.com
Koyeb is a high‑performance Serverless platform for AI inference, fine‑tuning, and distributed systems. It supports GPU/CPU/accelerator workloads in 50+ locations, delivering sub‑100ms global latency. Cold starts are under 200ms, scaling from zero to hundreds of servers. It’s optimized for AI workloads and supports RTX‑4000, L4, A100 and more, with transparent per‑second billing that can save up to 80% vs traditional cloud providers.
- Ultra‑fast cold starts under 200ms, instant scaling to hundreds of instances
- Global coverage with 50+ locations for low latency
- Hardware options from RTX‑4000 to A100, starting at $0.50/hr
Zhilingyun: Localized Serverless AI compute platform
Portal: https://datastone.cn
Zhilingyun is a Serverless ML platform by Hunan Panyun Data, focused on cost‑effective GPU services for Chinese developers. It supports one‑click deployment of models like DeepSeek, and offers templates for Stable Diffusion, Jupyter Notebook, ChatGLM, etc. It uses elastic billing—no charge when idle. Optimized for China‑specific needs, it supports Baidu Netdisk and Alibaba Cloud Drive sync, plus 75% off off‑peak pricing to reduce costs.
- Local optimizations: one‑click DeepSeek deployment, Baidu/Alibaba cloud drive sync
- 20+ templates including Stable Diffusion, ComfyUI, ChatGLM
- Flexible pricing: off‑peak 75% discount, RTX 4090D as low as ¥0.8/hr
Beam: AI infrastructure for developers
Portal: https://www.beam.cloud
Beam is an AI infrastructure platform offering serverless GPU inference and training. Its core idea is to let developers write code locally and execute instantly on cloud GPUs, giving a seamless cloud‑dev experience. Beam can containerize any Python function and deploy it to GPUs, with fast build times and auto scaling. It’s well suited for LangChain apps, Stable Diffusion APIs, or Dreambooth, and supports scheduled jobs, queues, and high‑performance distributed file systems.
- Cloud‑dev experience: local development with remote execution and instant GPU access
- One‑click containerization: deploy Python functions via decorators without complex setup
- Multi‑scenario deployment: REST APIs, scheduled jobs, queues, and more