We Struggled with GPU Compute Too — So We Built a Cloud Host
As a small team focused on AI, we’ve struggled with compute shortages just like many developers on the road to model training.
Expensive GPUs, long queues on mainstream cloud platforms, complex environment setup, and money burned by idle instances — that used to be our daily life. We wasted time waiting and doing ops instead of focusing on algorithms and product innovation.
We were done with that inefficiency. To solve our own problem, we decided to build the GPU cloud platform we always wanted: simple, efficient, and affordable.
We prepared a 10‑RMB compute voucher. Register here to claim it: Get a 10‑RMB no‑threshold voucher
How We Solve the Shared Pain Points
We turned every pitfall we hit into the core features of Gongji Compute:
-
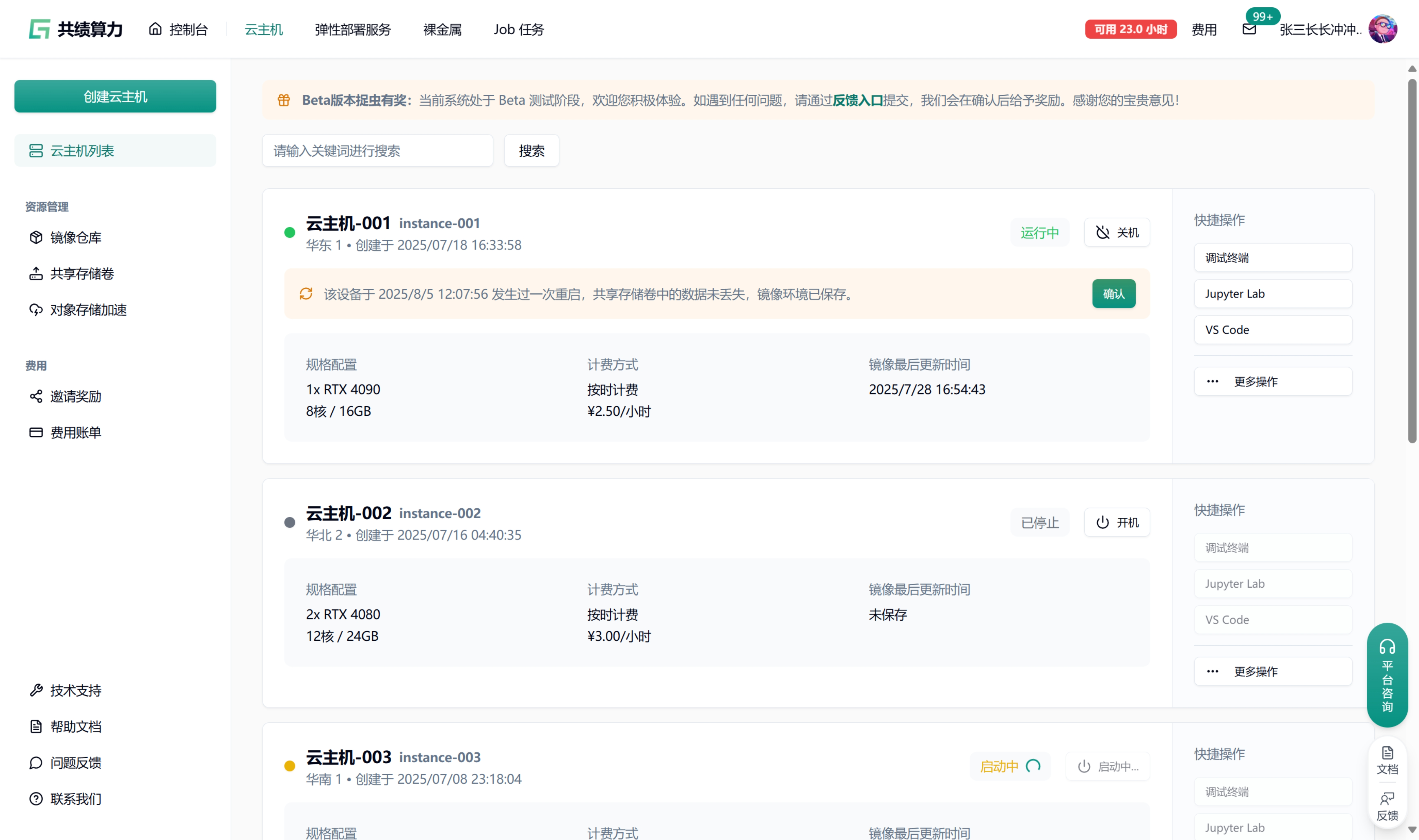
No more queues — start instantly: We invested heavily to reserve thousands of RTX 4090/5090 GPUs. No waiting; jump into Jupyter Lab, VS Code, or Bash right in the browser anytime.
-
Pay only for effective compute: We believe not a cent should be wasted on idle time. We implemented true per‑second billing — stop the instance, stop the charges; start/stop is free. RTX 4090 costs only 1.68 RMB/hour — pay only for what you use.
-
Three‑minute onboarding, focus on dev: We preinstall mainstream images including PyTorch, TensorFlow, ComfyUI, Stable Diffusion, and more. No more environment setup headaches — everything works out of the box.
-
Data 安心: We provide shared storage volumes and S3 mount acceleration so your datasets, code, and model weights move safely and efficiently between tasks.
We Chase Extreme Cost Performance
We use ourselves as the first users and optimized the most painful steps in development. Our goal is to deliver the most stable, smooth experience at the same price.
| Dimension | Gongji Compute | What it solves |
|---|---|---|
| Availability | Thousands of RTX 4090/5090 in stock | No queues, start instantly. |
| Price | 4090: 1.68 RMB/hr, 5090: 2.5 RMB/hr | 30–60% cheaper than mainstream clouds. |
| Billing | Per‑second billing, stopped instances free | No more paying for idle time. |
| Startup speed | Enter dev environment within 3 minutes | Goodbye long waits. |
| Environment | Preinstalled common images, built‑in Tsinghua pip mirror | No environment setup pain. |
| Collaboration | One‑click image distribution for teachers/leads | Team collab and training efficiency. |
Real‑World Performance
We also use Gongji Compute for model fine‑tuning and prototype development. Some real cost/performance references:
- Llama 3 fine‑tuning: single RTX 4090, Llama‑3‑8B LoRA fine‑tune, ~4 hours costs about 6.7 RMB; free after shutdown.
- Kaggle competitions: rent 8 RTX 4090s for 30 minutes, release after; total cost < 80 RMB.
- AI teaching: teachers distribute prebuilt images to hundreds of students; shut down after class, cost per student less than a milk tea.
- Service deployment: after tuning in ComfyUI, package directly into elastic API service — no second deployment.
Quick Start
We designed onboarding to be very simple — your first task can run in about three minutes:
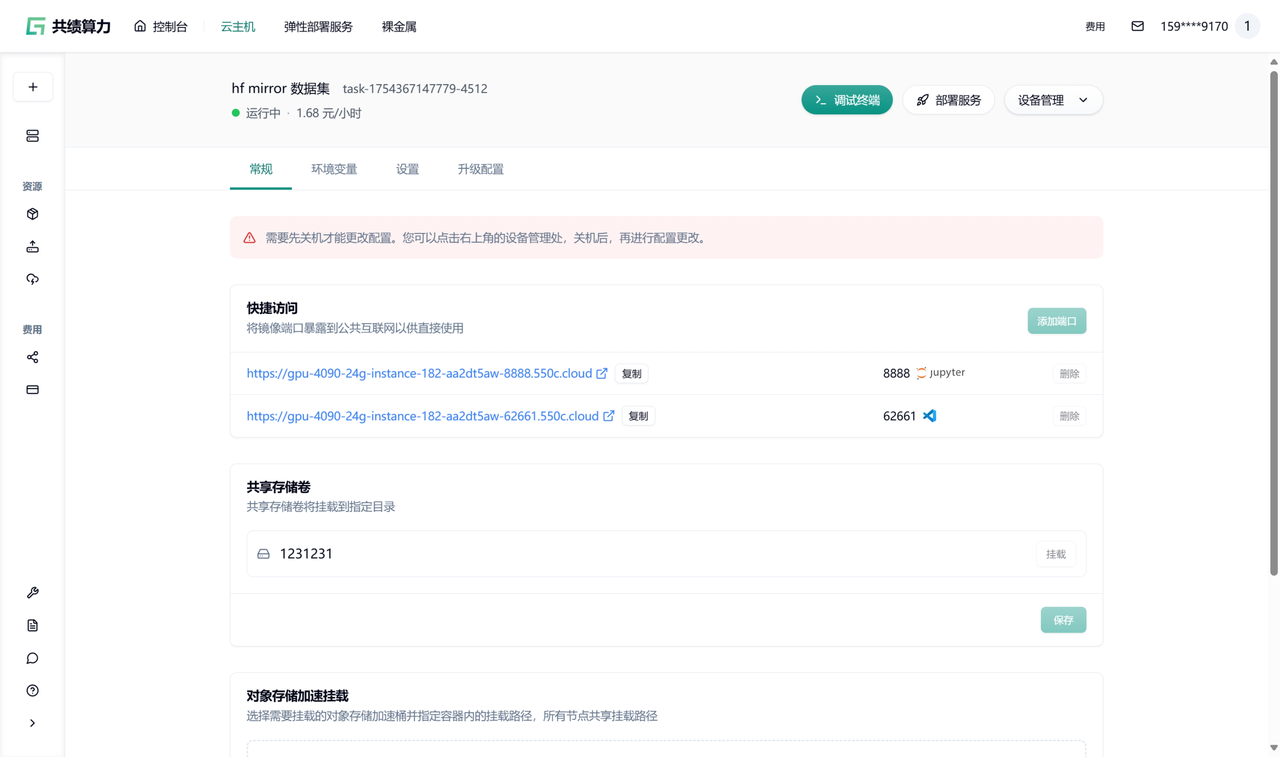
- Go to the Gongji Compute console and open Cloud Host.
- Select the GPU type and quantity you need.
- Name your instance and choose a prebuilt base image.
- Optionally attach a shared storage volume for persistence.
- Click Create Instance.
Now you can fully enjoy AI development.
We prepared a 10‑RMB compute voucher — register via the link below to claim it. We hope Gongji Compute becomes the perfect “alchemy” tool in your hands.